publications
2025
-
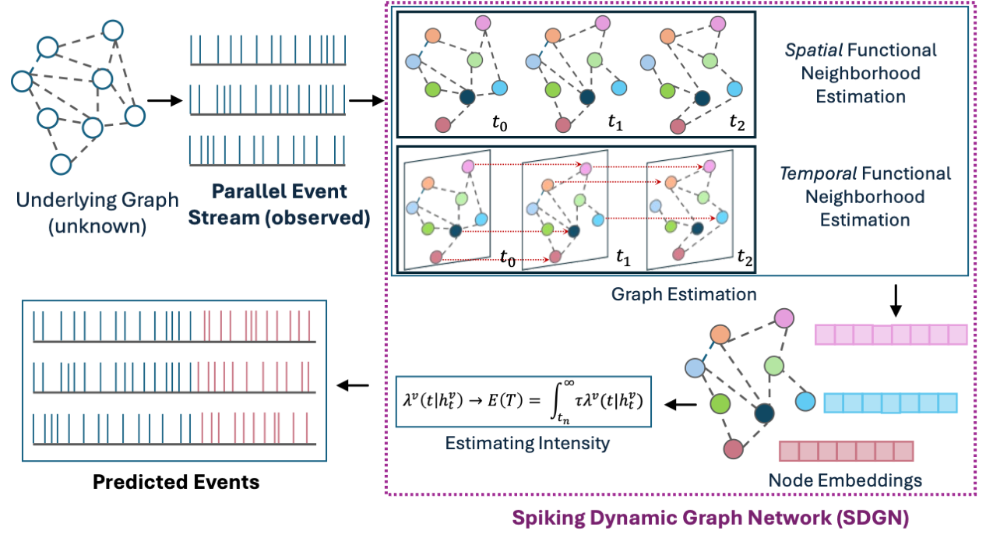 Dynamic Graph Structure Estimation for Learning Multivariate Point Process using Spiking Neural NetworksBiswadeep Chakraborty, Hemant Kumawat, Beomseok Kang, and 1 more author2025 International Joint Conference on Neural Networks (IJCNN 2025), 2025
Dynamic Graph Structure Estimation for Learning Multivariate Point Process using Spiking Neural NetworksBiswadeep Chakraborty, Hemant Kumawat, Beomseok Kang, and 1 more author2025 International Joint Conference on Neural Networks (IJCNN 2025), 2025Modeling and predicting temporal point processes (TPPs) is critical in domains such as neuroscience, epidemiology, finance, and social sciences. We introduce the Spiking Dynamic Graph Network (SDGN), a novel framework that leverages the temporal processing capabilities of spiking neural networks (SNNs) and spike-timing-dependent plasticity (STDP) to dynamically estimate underlying spatio-temporal functional graphs. Unlike existing methods that rely on predefined or static graph structures, SDGN adapts to any dataset by learning dynamic spatio-temporal dependencies directly from the event data, enhancing generalizability and robustness. While SDGN offers significant improvements over prior methods, we acknowledge its limitations in handling dense graphs and certain non-Gaussian dependencies, providing opportunities for future refinement. Our evaluations, conducted on both synthetic and real-world datasets including NYC Taxi, 911, Reddit, and Stack Overflow, demonstrate that SDGN achieves superior predictive accuracy while maintaining computational efficiency. Furthermore, we include ablation studies to highlight the contributions of its core components.
-
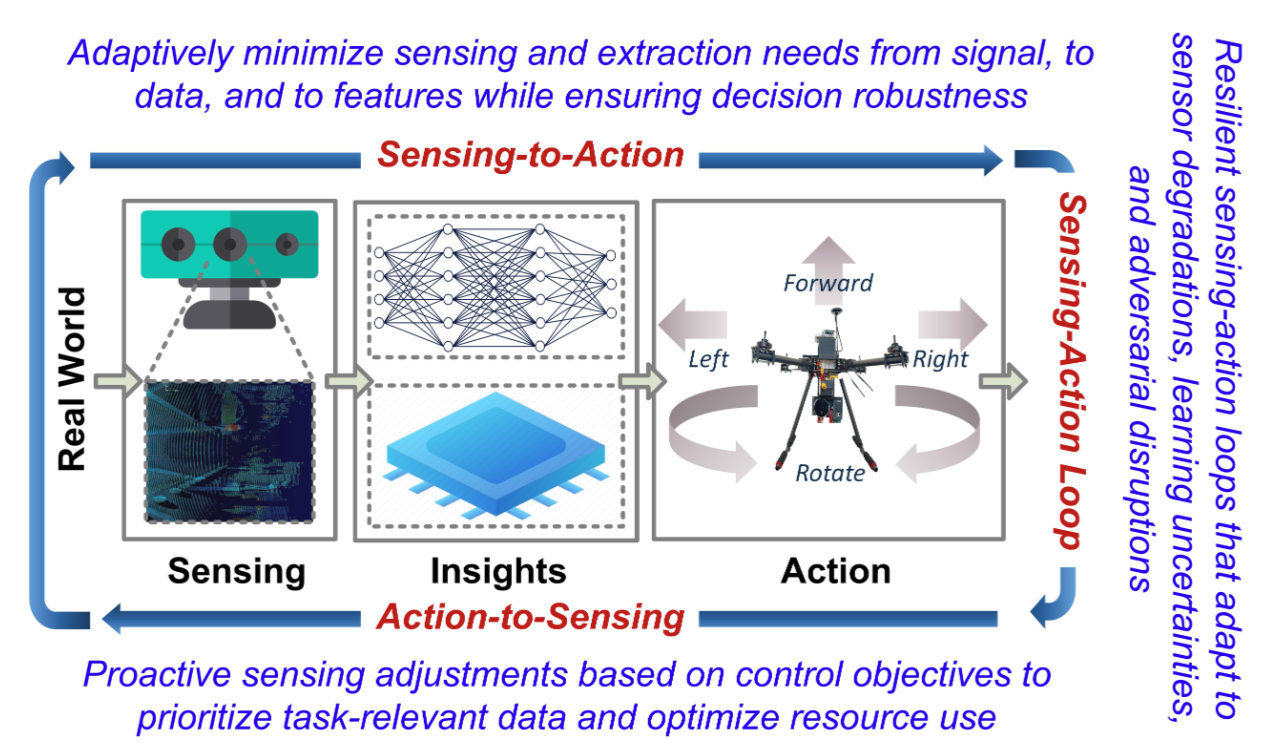 Intelligent Sensing-to-Action for Robust Autonomy at the Edge: Opportunities and ChallengesAmit Ranjan Trivedi, Hemant Kumawat, Sina Tayebati, and 9 more authorsTo appear in Design Automation and Test in Europe (DATE) 2025, 2025
Intelligent Sensing-to-Action for Robust Autonomy at the Edge: Opportunities and ChallengesAmit Ranjan Trivedi, Hemant Kumawat, Sina Tayebati, and 9 more authorsTo appear in Design Automation and Test in Europe (DATE) 2025, 2025Autonomous edge computing in robotics, smart cities, and autonomous vehicles relies on the seamless integration of sensing, processing, and actuation for real-time decision-making in dynamic environments. At its core is the sensing-to-action loop, which iteratively aligns sensor inputs with computational models to drive adaptive control strategies. These loops can adapt to hyper-local conditions, enhancing resource efficiency and responsiveness, but also face challenges such as resource constraints, synchronization delays in multi-modal data fusion, and the risk of cascading errors in feedback loops. This article explores how proactive, context-aware sensing-to-action and action-to-sensing adaptations can enhance efficiency by dynamically adjusting sensing and computation based on task demands, such as sensing a very limited part of the environment and predicting the rest. By guiding sensing through control actions, action-to-sensing pathways can improve task relevance and resource use, but they also require robust monitoring to prevent cascading errors and maintain reliability. Multi-agent sensing-action loops further extend these capabilities through coordinated sensing and actions across distributed agents, optimizing resource use via collaboration. Additionally, neuromorphic computing, inspired by biological systems, provides an efficient framework for spike-based, event-driven processing that conserves energy, reduces latency, and supports hierarchical control–making it ideal for multi-agent optimization. This article highlights the importance of end-to-end co-design strategies that align algorithmic models with hardware and environmental dynamics and improve cross-layer interdependencies to improve throughput, precision, and adaptability for energy-efficient edge autonomy in complex environments.
-
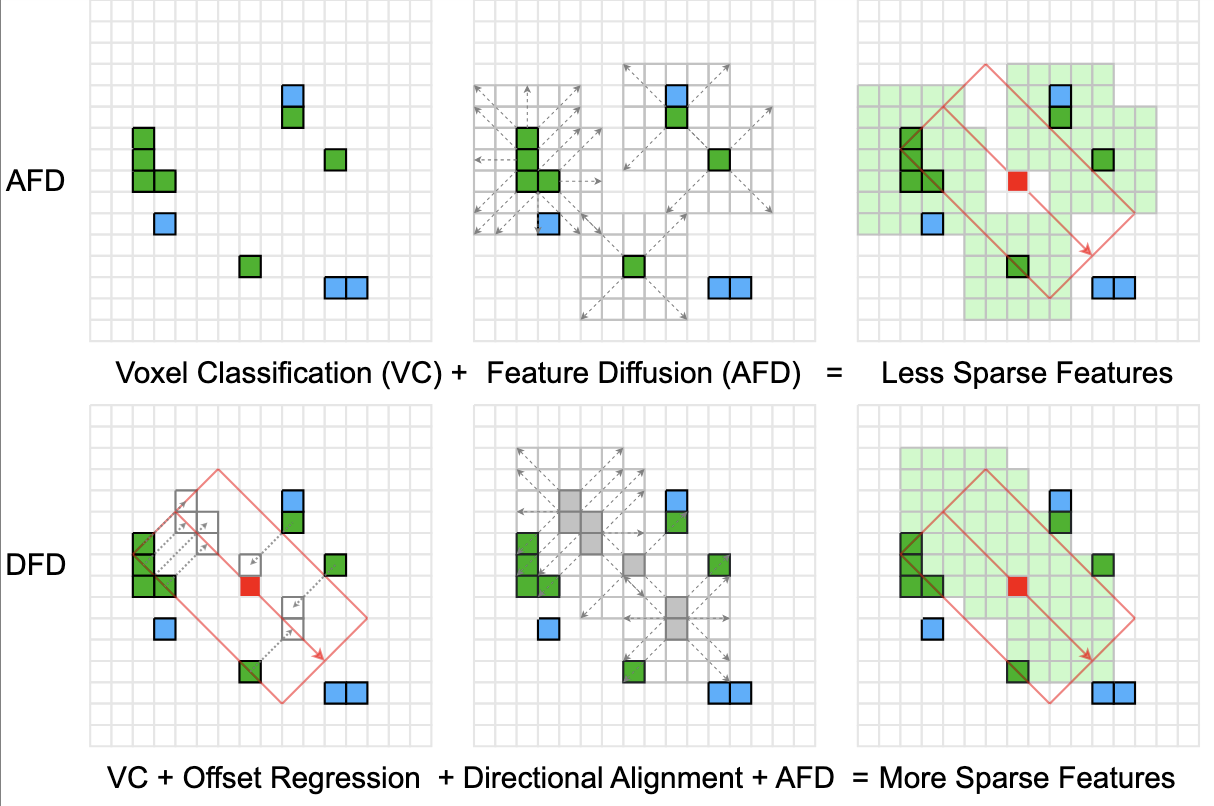 Adaptive Feature Diffusion for Low Compute LiDAR Object DetectionMeilong Zhang, Hemant Kumawat, and Saibal MukhopadhyayUnder review at CVPR 2025, 2025
Adaptive Feature Diffusion for Low Compute LiDAR Object DetectionMeilong Zhang, Hemant Kumawat, and Saibal MukhopadhyayUnder review at CVPR 2025, 2025 -
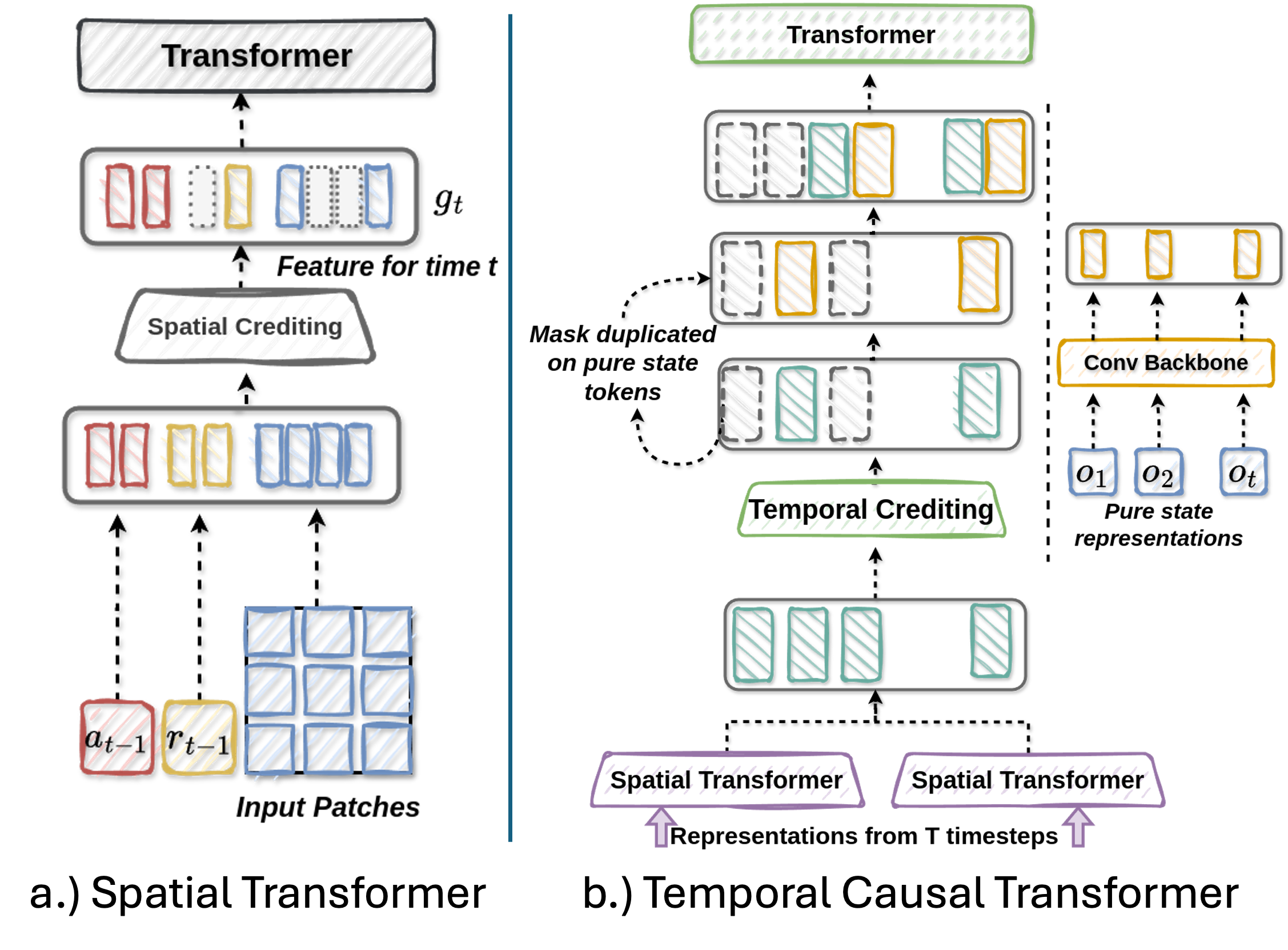 AdaCred: Adaptive Causal Decision Transformers with Feature CreditingHemant Kumawat, and Saibal MukhopadhyayProc. of the 24th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2025), 2025
AdaCred: Adaptive Causal Decision Transformers with Feature CreditingHemant Kumawat, and Saibal MukhopadhyayProc. of the 24th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2025), 2025Reinforcement learning (RL) can be viewed as a sequence modeling challenge, where the goal is to predict future actions based on past state-action-reward sequences. Traditional methods often rely on long trajectory sequences to capture environmental dynamics in offline RL scenarios. However, this can lead to a tendency to overemphasize the memorization of long-term representations, which hinders the models’ ability to prioritize trajectories and learned representations that are specifically relevant to the task at hand. In this study, we present AdaDT, a novel approach that conceptualizes trajectories as causal graphs derived from short-term action-reward-state sequences. Our model dynamically adapts its control policy by identifying and eliminating low-importance representations, focusing instead on those that are most pertinent to the downstream task. Experimental results show that policies based on AdaDT require shorter trajectory sequences and consistently outperform traditional methods in both offline reinforcement learning and imitation learning settings.
2024
-
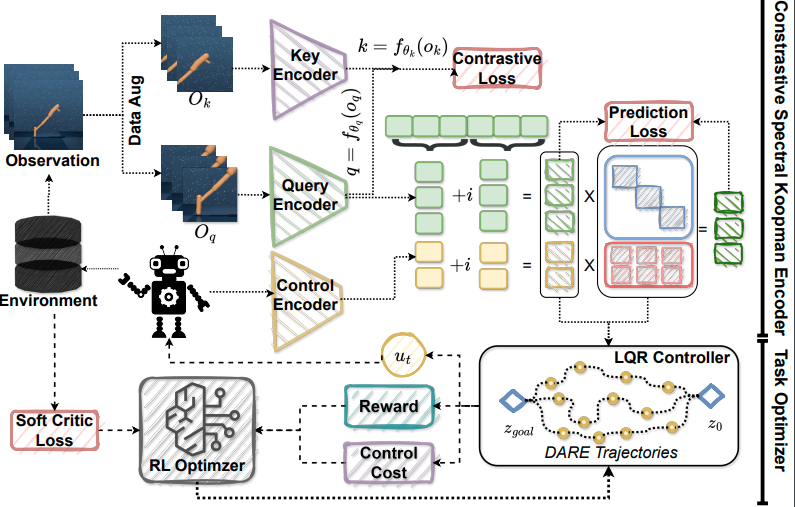 RoboKoop: Efficient Control Conditioned Representations from Visual Input in Robotics using Koopman OperatorHemant Kumawat, Biswadeep Chakraborty, and Saibal MukhopadhyayIn 62024 Conference on Robot Learning, 2024
RoboKoop: Efficient Control Conditioned Representations from Visual Input in Robotics using Koopman OperatorHemant Kumawat, Biswadeep Chakraborty, and Saibal MukhopadhyayIn 62024 Conference on Robot Learning, 2024Developing agents that can perform complex control tasks from high- dimensional observations is a core ability of autonomous agents that requires un- derlying robust task control policies and adapting the underlying visual represen- tations to the task. Most existing policies need a lot of training samples and treat this problem from the lens of two-stage learning with a controller learned on top of pre-trained vision models. We approach this problem from the lens of Koopman theory and learn visual representations from robotic agents conditioned on spe- cific downstream tasks in the context of learning stabilizing control for the agent. We introduce a Contrastive Spectral Koopman Embedding network that allows us to learn efficient linearized visual representations from the agent’s visual data in a high dimensional latent space and utilizes reinforcement learning to perform off-policy control on top of the extracted representations with a linear controller. Our method enhances stability and control in gradient dynamics over time, signif- icantly outperforming existing approaches by improving efficiency and accuracy in learning task policies over extended horizons.
-
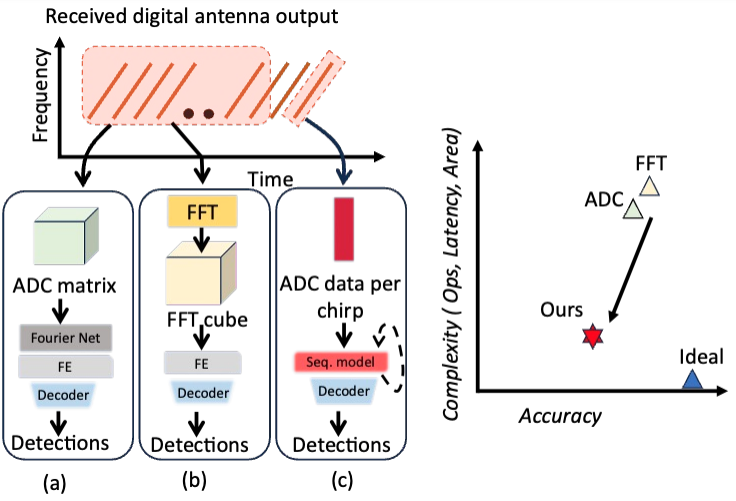 ChirpNet: Noise-Resilient Sequential Chirp Based Radar Processing for Object DetectionSudarshan Sharma**, Hemant Kumawat**, and Saibal MukhopadhyayIn 2024 IEEE/MTT-S International Microwave Symposium - IMS 2024 (**equal contribution), 2024
ChirpNet: Noise-Resilient Sequential Chirp Based Radar Processing for Object DetectionSudarshan Sharma**, Hemant Kumawat**, and Saibal MukhopadhyayIn 2024 IEEE/MTT-S International Microwave Symposium - IMS 2024 (**equal contribution), 2024Radar-based object detection (OD) requires extensive pre-processing and complex Machine Learning (ML) pipelines. Previous approaches have attempted to address these challenges by processing raw radar data frames directly from the ADC or through FFT-based post-processing. However, the input data requirements and model complexity continue to impose significant computational overhead on the edge system. In this work, we introduce ChirpNet, a noise-resilient and efficient radar processing ML architecture for object detection. Diverging from previous approaches, we directly handle raw ADC data from multiple antennas per chirp using a sequential model, resulting in a substantial 15 × reduction in complexity and a 3 × reduction in latency, while maintaining competitive OD performance. Furthermore, our proposed scheme is robust to input noise variations compared to prior works.
-
 STEMFold: Stochastic temporal manifold for multi-agent interactions in the presence of hidden agentsHemant Kumawat, Biswadeep Chakraborty, and Saibal MukhopadhyayIn 6th Annual Learning for Dynamics & Control Conference, 15-17 July 2024, University of Oxford, Oxford, UK, 2024
STEMFold: Stochastic temporal manifold for multi-agent interactions in the presence of hidden agentsHemant Kumawat, Biswadeep Chakraborty, and Saibal MukhopadhyayIn 6th Annual Learning for Dynamics & Control Conference, 15-17 July 2024, University of Oxford, Oxford, UK, 2024Learning accurate, data-driven predictive models for multiple interacting agents following un- known dynamics is crucial in many real-world physical and social systems. In many scenarios, dynamics prediction must be performed under incomplete observations, i.e., only a subset of agents are known and observable from a larger topological system while the behaviors of the unobserved agents and their interactions with the observed agents are not known. When only incomplete obser- vations of a dynamical system are available, so that some states remain hidden, it is generally not possible to learn a closed-form model in these variables using either analytic or data-driven tech- niques. In this work, we propose STEMFold, a spatiotemporal attention-based generative model, to learn a stochastic manifold to predict the underlying unmeasured dynamics of the multi-agent system from observations of only visible agents. Our analytical results motivate STEMFold design using a spatiotemporal graph with time anchors to effectively map the observations of visible agents to a stochastic manifold with no prior information about interaction graph topology. We empirically evaluated our method on two simulations and two real-world datasets, where it outperformed exist- ing networks in predicting complex multiagent interactions, even with many unobserved agents.
- STAGE Net: Spatio-Temporal Attention-based Graph Encoding for Learning Multi-Agent Interactions in the presence of Hidden AgentsHemant Kumawat, Biswadeep Chakraborty, and Saibal MukhopadhyayIn Under Review at ICLR 2023, 2024
Accurate prediction of trajectories for multiple interacting agents following unknown dynamics is crucial in many real-world critical physical and social systems where a group of agents interact with each other, leading to intricate behavior patterns at both the individual and system levels. In many scenarios, trajectory predictions must be performed under partial observations i.e., only a subset of agents are known and observable. Consequently, we can only observe the trajectories of a subset of agents with a sampled interaction graph from a larger topological system while the behaviors of the unobserved agents and their interactions with the observed agents are not known. In this work, we propose STAGE Net, a sequential spatiotemporal attention-based generative model to learn system dynamics with multiple interacting agents where some agents are completely unobserved (hidden) all the time. Our network utilizes the spatiotemporal attention mechanism with neural inter-node messaging to capture high-level behavioral semantics of the multi-agent system. Our analytical results motivate STAGE Net design using spatiotemporal graph with time anchors to effectively model complex multi-agent interactions with unobserved agents and no prior information about interaction graph topology. We evaluate our method on multiagent simulations with spring and charged dynamics and a motion trajectory dataset. Empirical results illustrate that our method outperforms existing multiagent interaction modeling networks in predicting trajectories of complex multiagent interactions even when we have a large number of unobserved agents.
-
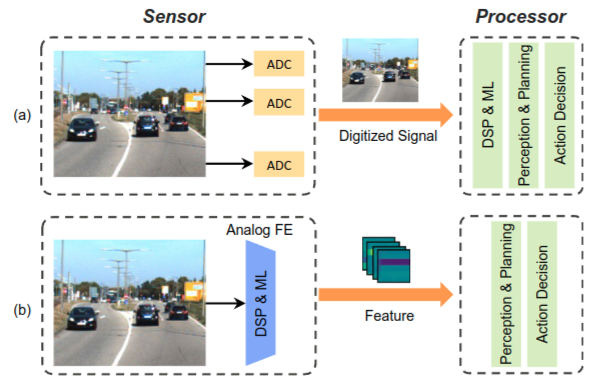 Cognitive Sensing for Energy-Efficient Edge IntelligenceMinah Lee, Sudarshan Sharma, Wei Chun Wang, and 3 more authorsIn 2024 Design, Automation & Test in Europe Conference & Exhibition (DATE), 2024
Cognitive Sensing for Energy-Efficient Edge IntelligenceMinah Lee, Sudarshan Sharma, Wei Chun Wang, and 3 more authorsIn 2024 Design, Automation & Test in Europe Conference & Exhibition (DATE), 2024Edge platforms in autonomous systems integrate multiple sensors to interpret their environment. The high-resolution and high-bandwidth pixel arrays of these sensors improve sensing quality but also generate a vast, and arguably unnecessary, volume of real-time data. This challenge, often referred to as the analog data deluge, hinders the deployment of high-quality sensors in resource-constrained environments. This paper discusses the concept of cognitive sensing, which learns to extract low-dimensional features directly from high-dimensional analog signals, thereby reducing both digitization power and generated data volume. First, we discuss design methods for analog-to-feature extraction (AFE) using mixed-signal compute-in-memory. We then present examples of cognitive sensing, incorporating signal processing or machine learning, for various sensing modalities including vision, Radar, and Infrared. Subsequently, we discuss the reliability challenges in cognitive sensing, taking into account hardware and algorithmic properties of AFE. The paper concludes with discussions on future research directions in this emerging field of cognitive sensors.
2022
-
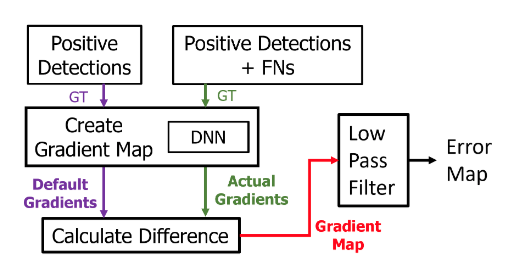 A Methodology for Understanding the Origins of False Negatives in DNN Based Object DetectorsKruttidipta Samal, Hemant Kumawat, Marilyn Wolf, and 1 more authorIn 2022 International Joint Conference on Neural Networks (IJCNN), 2022
A Methodology for Understanding the Origins of False Negatives in DNN Based Object DetectorsKruttidipta Samal, Hemant Kumawat, Marilyn Wolf, and 1 more authorIn 2022 International Joint Conference on Neural Networks (IJCNN), 2022In this paper we present two novel complimentary methods namely the gradient analysis and the activation discrepancy analysis to analyze the perception failures occurring inside the DNN based object detectors. The gradient analysis localizes the nodes within the network that fail consistently in a scenario, thus creating a ‘signature’ of False Negatives (FNs). This method traces a set of False Negatives through the network and finds sections of the network that contribute to this set. The signatures show the location of the faulty nodes is sensitive to input conditions (such as darkness, glare etc.), network architecture, training hyperparameters, object class etc. Certain nodes of the network fail consistently throughout the training process thus implying that some False Negatives occur due to the global optimization nature of Stochastic Gradient Descent (SGD) based training. This analysis requires the knowledge of False Negatives and therefore can be used for post-hoc diagnostic analysis. On the other hand, the activation discrepancy analysis analyzes the discrepancy in forward activations of a DNN. This method can be conducted online and shows that the pattern of the activation discrepancy is sensitive to input conditions and detection recall.
-
 Radar Guided Dynamic Visual Attention for Resource-Efficient RGB Object DetectionHemant Kumawat, and Saibal MukhopadhyayIn 2022 International Joint Conference on Neural Networks (IJCNN), 2022
Radar Guided Dynamic Visual Attention for Resource-Efficient RGB Object DetectionHemant Kumawat, and Saibal MukhopadhyayIn 2022 International Joint Conference on Neural Networks (IJCNN), 2022An autonomous system’s perception engine must provide an accurate understanding of the environment for it to make decisions. Deep learning based object detection networks experience degradation in the performance and robustness for small and far away objects due to a reduction in object’s feature map as we move to higher layers of the network. In this work, we propose a novel radar-guided spatial attention for RGB images to improve the perception quality of autonomous vehicles operating in a dynamic environment. In particular, our method improves the perception of small and long range objects, which are often not detected by the object detectors in RGB mode. The proposed method consists of two RGB object detectors, namely the Primary detector and a lightweight Secondary detector. The primary detector takes a full RGB image and generates primary detections. Next, the radar proposal framework creates regions of interest (ROIs) for object proposals by projecting the radar point cloud onto the 2D RGB image. These ROIs are cropped and fed to the secondary detector to generate secondary detections which are then fused with the primary detections via non-maximum suppression. This method helps in recovering the small objects by preserving the object’s spatial features through an increase in their receptive field. We evaluate our fusion method on the challenging nuScenes dataset and show that our fusion method with SSD-lite as primary and secondary detector improves the baseline primary yolov3 detector’s recall by 14 % while requiring three times fewer computational resources.
-
 Task-Driven RGB-Lidar Fusion for Object Tracking in Resource-Efficient Autonomous SystemKruttidipta Samal, Hemant Kumawat, Priyabrata Saha, and 2 more authorsIEEE Transactions on Intelligent Vehicles, 2022
Task-Driven RGB-Lidar Fusion for Object Tracking in Resource-Efficient Autonomous SystemKruttidipta Samal, Hemant Kumawat, Priyabrata Saha, and 2 more authorsIEEE Transactions on Intelligent Vehicles, 2022Autonomous mobile systems such as vehicles or robots are equipped with multiple sensor modalities including Lidar, RGB, and Radar. The fusion of multi-modal information can enhance task accuracy but indiscriminate sensing and fusion in all modalities increase demand on available system resources. This paper presents a task-driven approach to input fusion that minimizes the utilization of resource-heavy sensors and demonstrates its application to Visual-Lidar fusion for object tracking and path planning. The proposed spatiotemporal sampling algorithm activates Lidar only at regions-of-interest identified by analyzing visual input and reduces the Lidar ‘base frame rate’ according to the kinematic state of the system. This significantly reduces Lidar usage, in terms of data sensed/transferred and potentially power consumed, without a severe reduction in performance compared to both a baseline decision-level fusion and state-of-the-art deep multi-modal fusion.